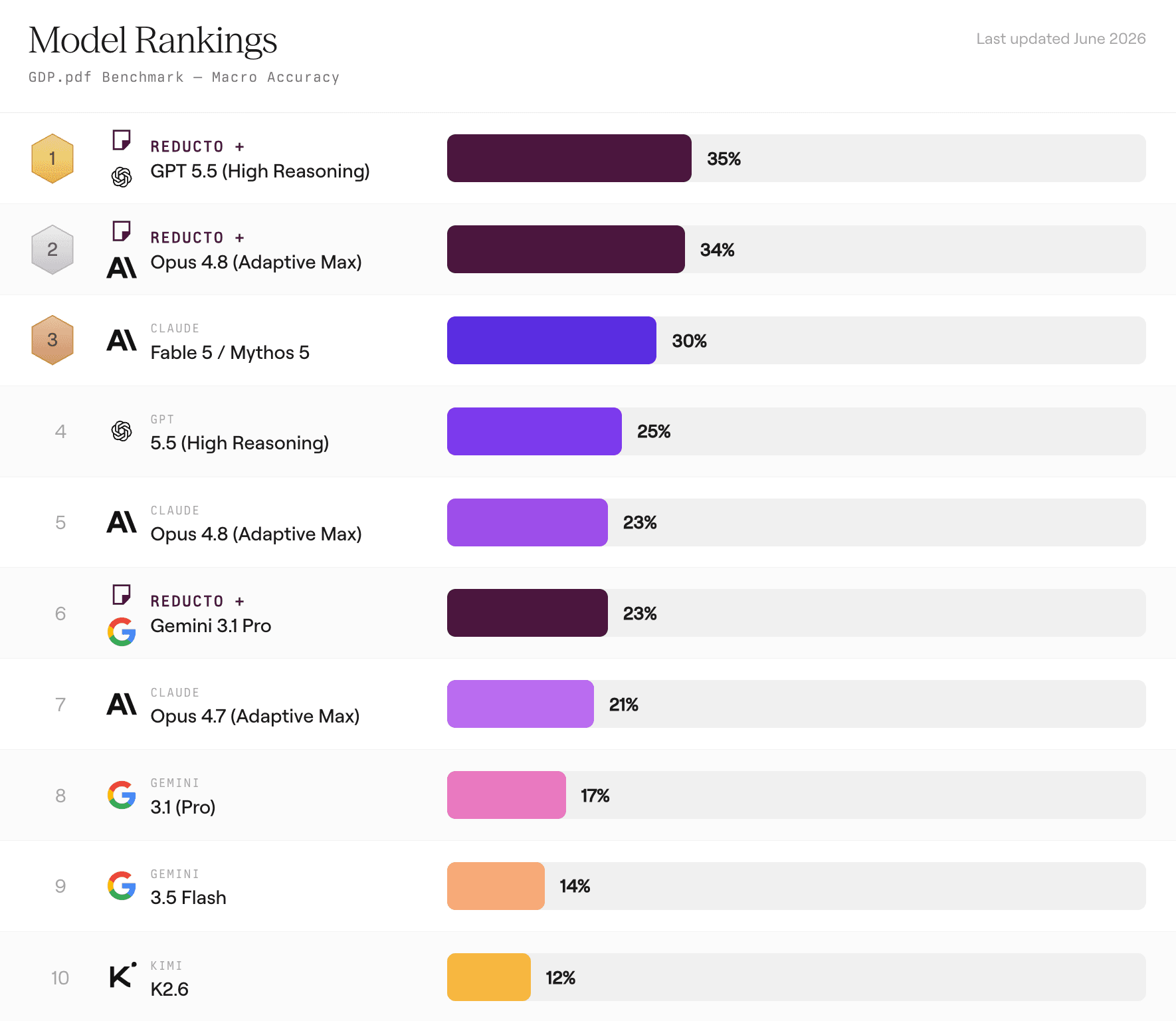
Reducto Raises Frontier Model Accuracy on GDP.pdf
Surge released GDP.pdf, a benchmark testing whether frontier models can answer expert questions about real-world professional documents: finance filings, dosage tables, indemnification clauses, and supply-chain manifests.
The results were sobering. The best model, Claude Fable 5, scored 30% on whole-task success with extended thinking enabled. GPT-5.5 hit 25%. Gemini 3.1 Pro, 17%. These are the most capable models available, running with maximum reasoning, and they still fail roughly three out of four times on expert document tasks.
Where Reducto can help
We commonly get asked why you'd use Reducto when a frontier model can already read a PDF. The answer is that this isn't build or buy – it's build with. Frontier models can parse documents on their own, but that parsing tends to be token-hungry, inconsistent across large corpuses, and prone to quiet errors: the merged cell, the dropped footnote, the misread that sends a capable model toward the wrong answer.
GDP.pdf gave us a clean way to test that. With a fresh set of genuinely hard documents in hand, we wanted to see whether pairing each PDF with Reducto's structured parse would lift downstream answer quality.
Our hypothesis: Adding Reducto's parse output alongside GDP.pdf inputs improves how well frontier models read, reason over, and complete real document tasks.
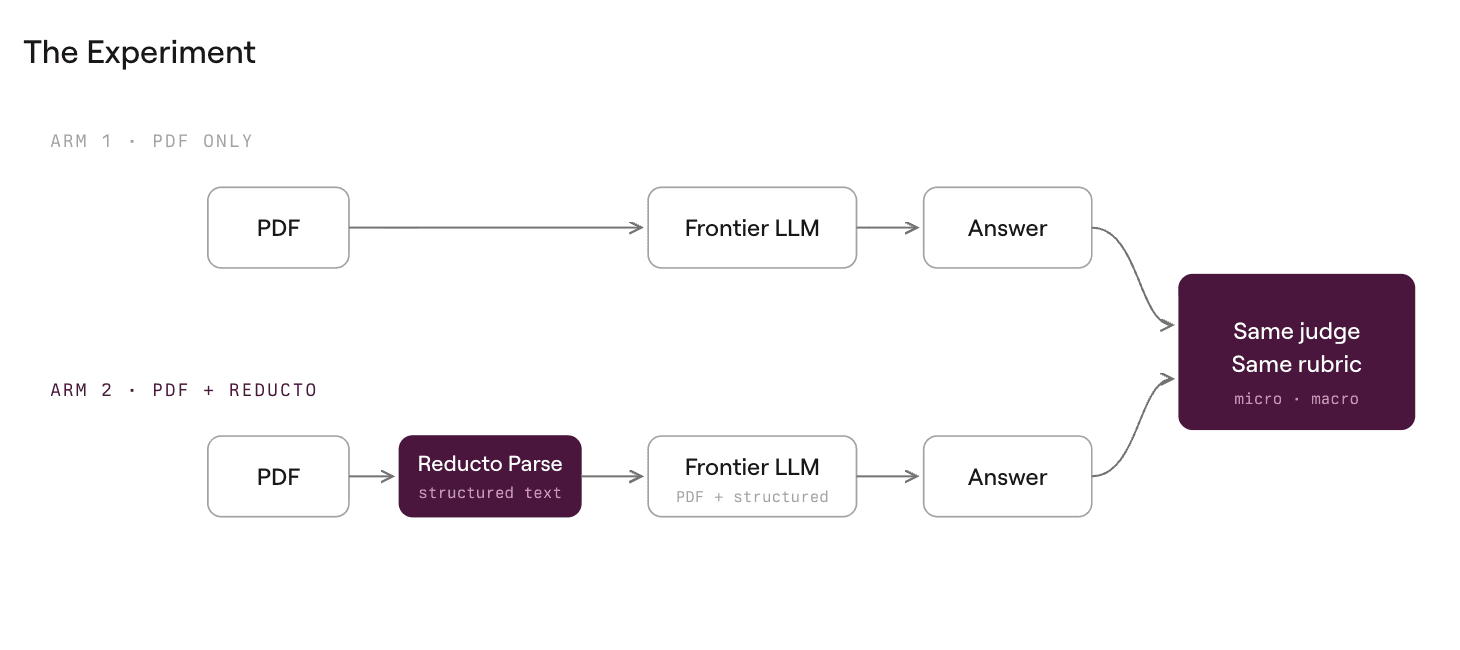
We ran two arms over the same 100 documents and the same models, then graded them identically using DeepSeek V4 Pro (text-only, reasoning enabled, pinned to a single provider). All experiments are fully reproducible; check out the GitHub repository.
- PDF (raw document).
- PDF + Reducto: the same document, plus Reducto's agentic parse as structured context (layout, tables, and text already resolved).
We tested across three frontier models: Gemini 3.1 Pro, GPT-5.5, and Claude Opus 4.8. Every reported number is measured over all 100 documents. We used max reasoning and adaptive thinking, exactly as Surge did, keeping the comparison fair across all arms.
Methodology
Numbers only mean something if the scoring is reliable so we were deliberate about two factors:
- We grade with DeepSeek V4 Pro, a model from a different family than every model under test, which removes family bias from grading.
- Grading is text-only against the prompt, the model's answer, and the rubric. Both arms are scored on identical, rubric-anchored evidence.
Results
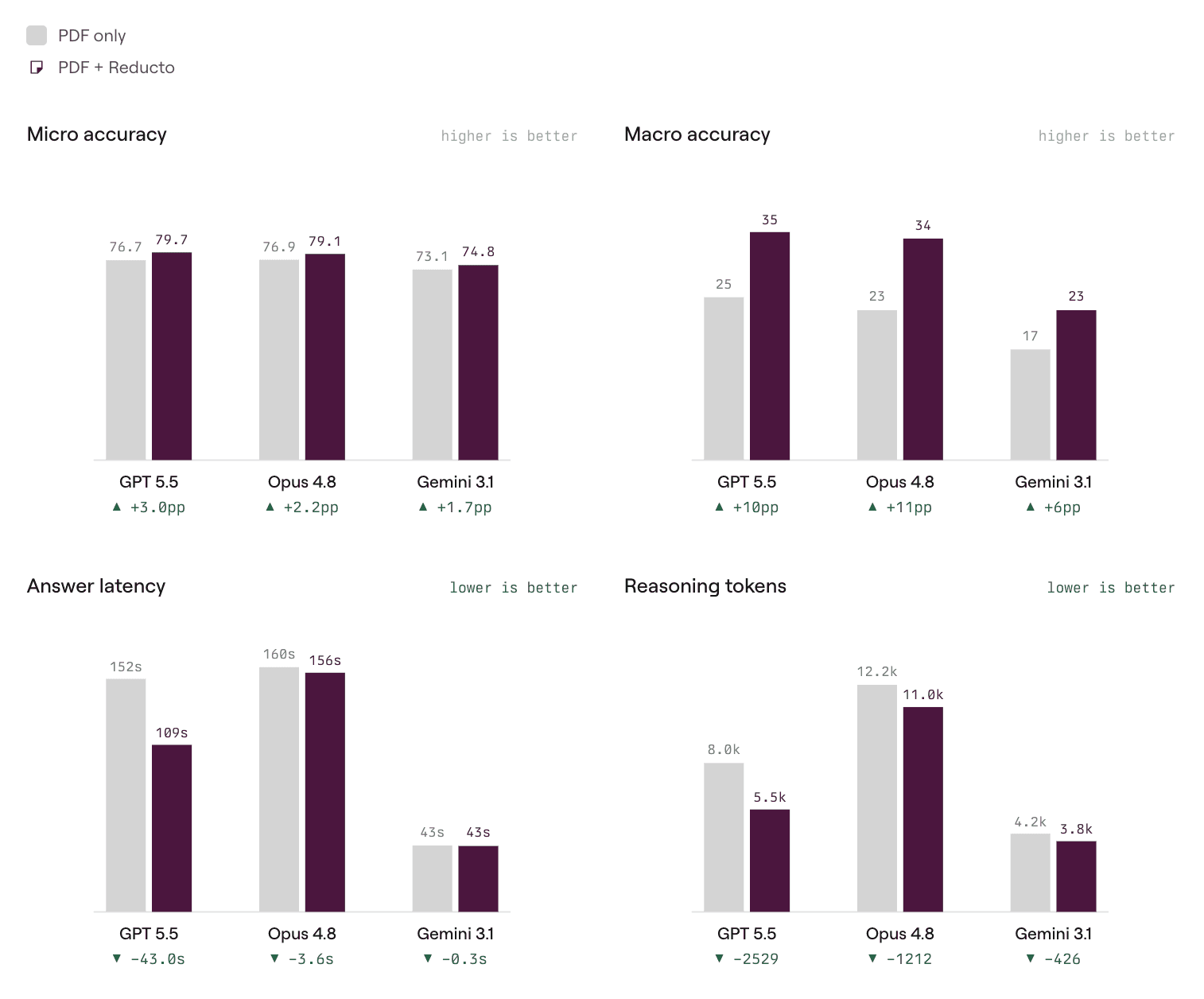
We track two accuracy metrics. Micro is the mean criteria pass rate: of all the individual things a rubric asks for, how many did the answer get? Macro is stricter, measuring the share of tasks where the model nailed every criterion. It is the "would you actually trust this output" number.
Macro jumps +9pp, from 21.7% to 30.7%, roughly 40% more fully-correct tasks Micro also rises +2.3pp (75.6% to 77.9%). Across all three models in aggregate, the macro gain (+9pp) is the more telling number with roughly 40% more tasks passing every rubric criterion.
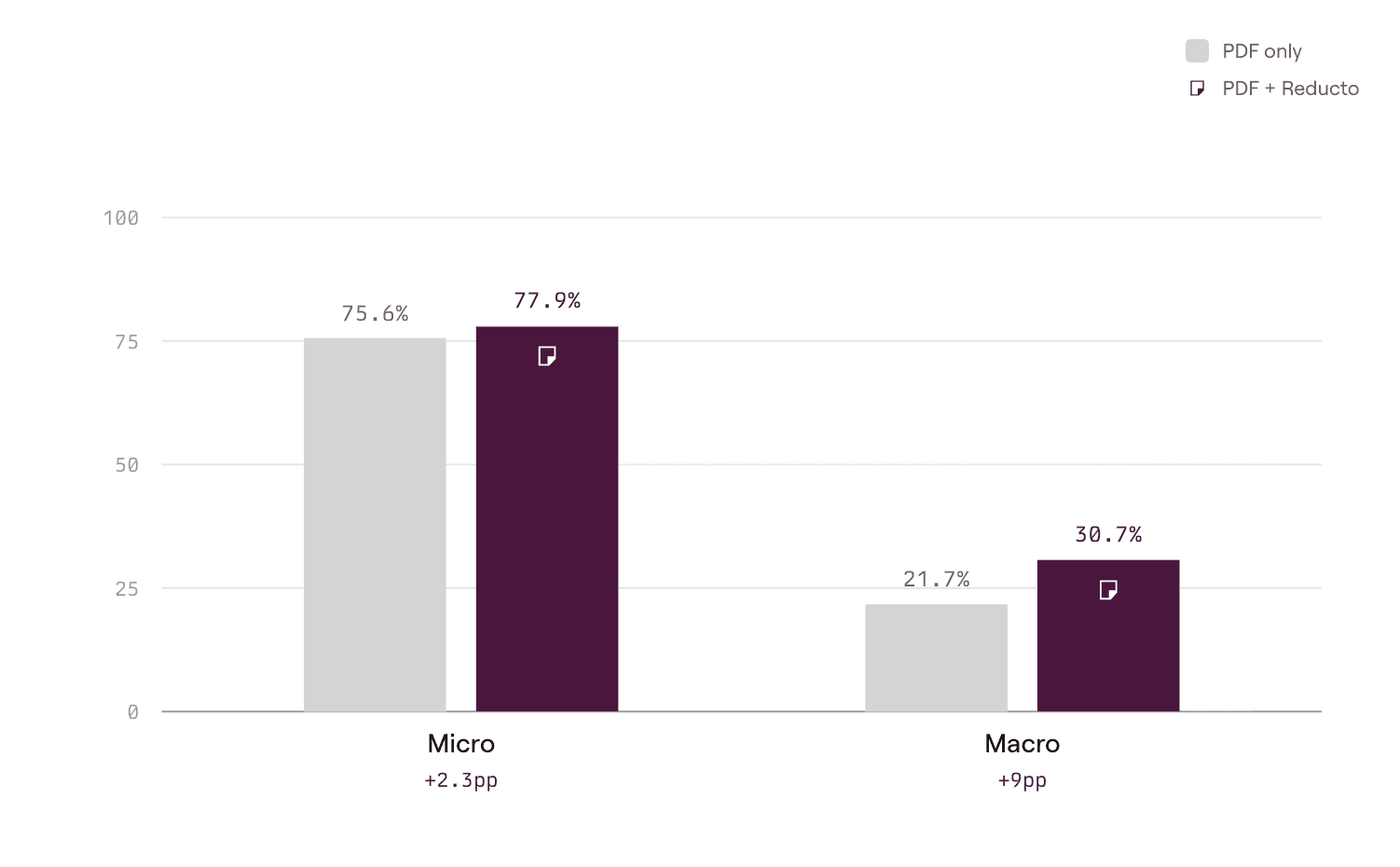
The lift is largest for the heaviest reasoners
Every model improved on whole-task success with parse data. The gains are largest for models that rely most on reasoning: Opus 4.8 gained +11pp on macro and GPT 5.5 gained +10pp. These are exactly the models that spend the most effort reconstructing document structure from raw pixels. Gemini 3.1 Pro also improved by +6pp.
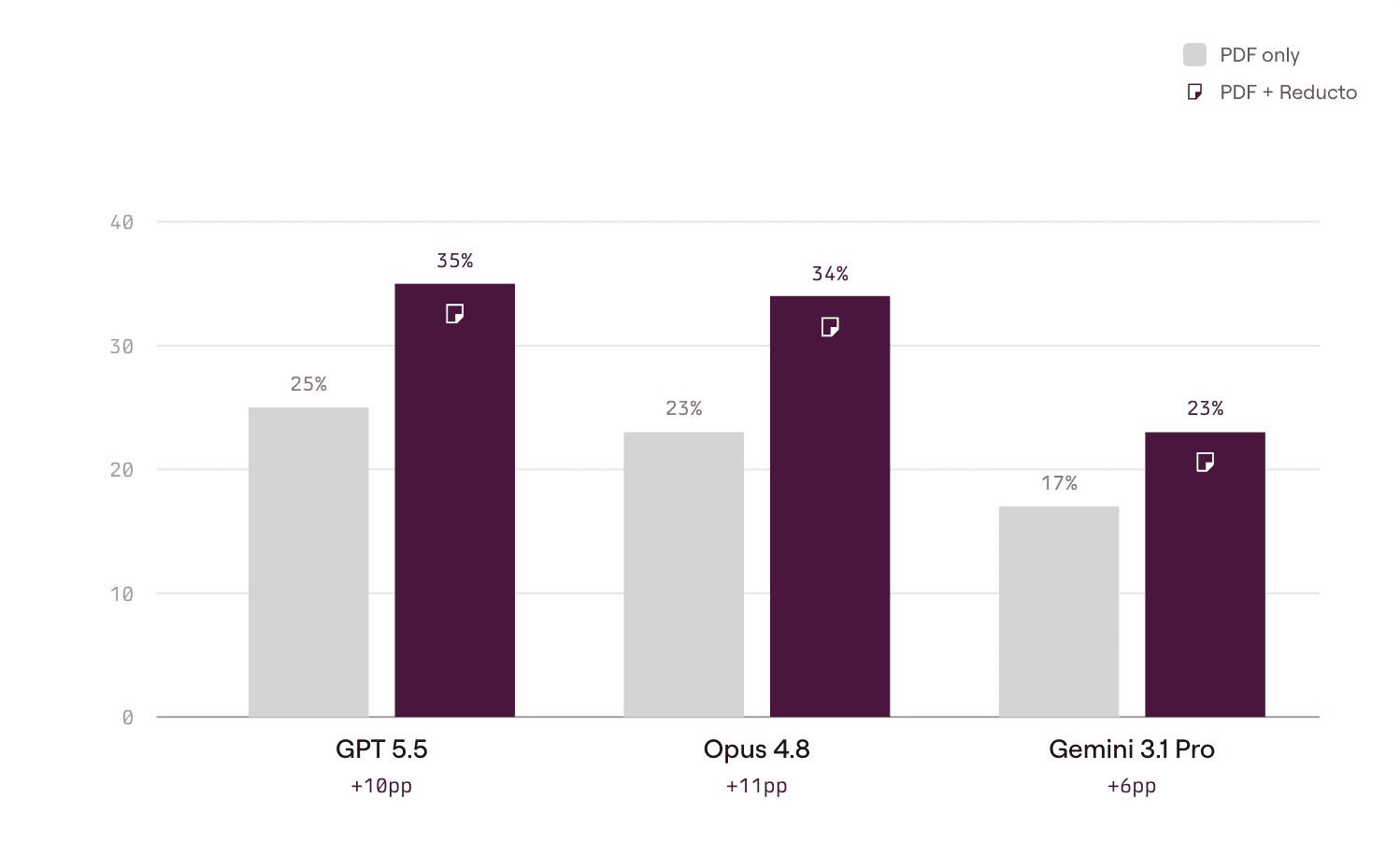
PDF only scores from Surge's published leaderboard. PDF + Reducto from Reducto's experimental run.
The gap between micro and macro reflects how many samples were close: models were nearly correct on most rubric criteria, and the parse pushed them over the finish line on the ones they were missing. The parse adds reliability and grounding that helps models reason over images and text together.
Full results across all four metrics:
Micro and macro baselines from Surge's published leaderboard. PDF + Reducto scores from Reducto's 100-sample experimental run.
*Note on reasoning tokens: Reasoning models bill per output token, and thinking tokens are the expensive ones. Adding Reducto's parse cut reasoning token usage by 13% in aggregate (8.8k to 7.7k per task). The effect is largest for GPT 5.5, which shed 33% of its reasoning tokens (7.6k to 5.5k). The model is no longer spending tokens reconstructing what the document says before it can start answering. For teams running reasoning models at scale, that reduction compounds quickly.
Where the gains are largest
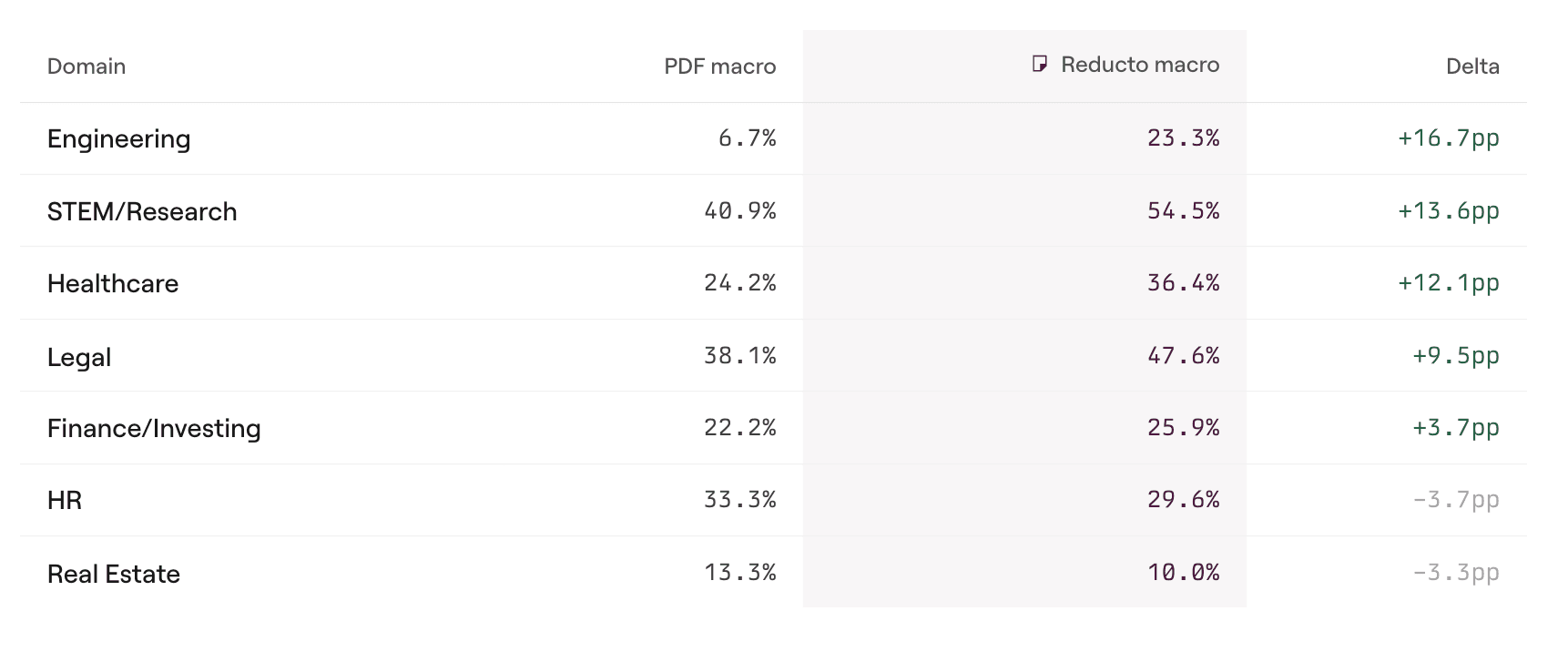
Engineering documents saw the biggest lift (+16.7pp macro), nearly tripling whole-task success from 6.7% to 23.3%. These are the densest documents in the benchmark: wiring diagrams, cross-referenced parts tables, serial-number-conditional instructions. STEM/Research (+13.6pp) and Healthcare (+12.1pp) also improved strongly.
Noticeably, HR and Real Estate industries saw small regressions; these documents are often prose-heavy, so the raw PDF already contains fewer layout ambiguities for the model to resolve. In those cases, structured parsing has less room to improve performance.
One engineering document in the benchmark is a commercial fryer service manual.
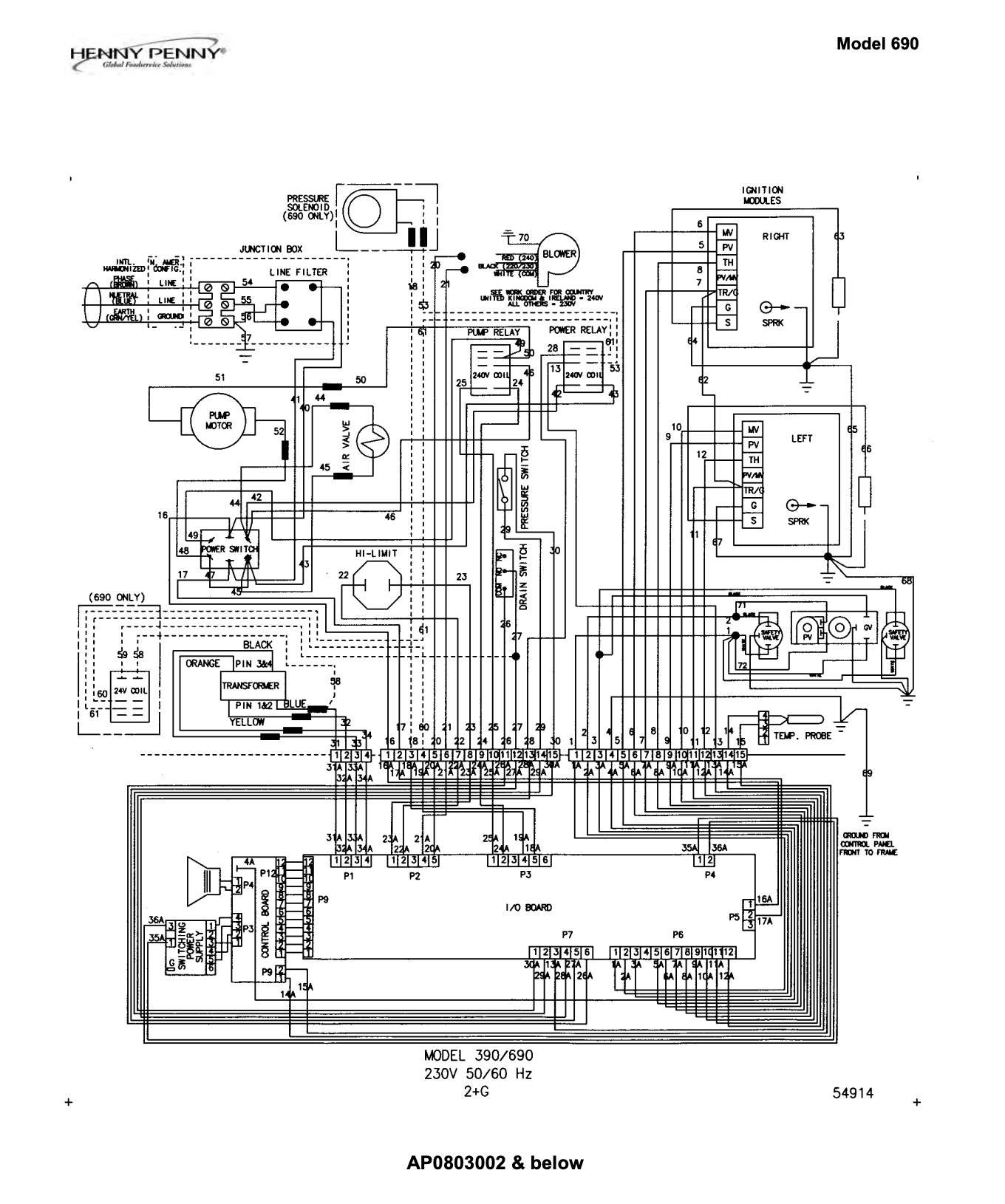
Question: For a model 690 fryer with serial number AP0709026, what is the name and number of the part connected to the I/O board via wire 31A?
Opus 4.8 on the raw PDF correctly identified the transformer assembly (part no. 60536) but then stated that wire 31A appeared on other wiring diagrams in the manual, when in reality it does not.
With Reducto's parse, the model answered cleanly, correctly scoped its answer to the right diagram, and passed all four criteria. The reasoning was fine in both cases. The failure came from misreading which diagram contained wire 31A and structured layout resolution eliminated that confusion.
More input tokens, but faster and economical at scale
Attaching the parse results drops answer generation latency by roughly 8% (120s to 111s), even as input tokens grow 82% (75k to 136k per task). The model burns fewer reasoning tokens reconstructing document layout, which cuts reasoning token usage by 13% (8.8k to 7.7k) and speeds up the final answer.
For production use cases where the same document is queried more than once, the right framing is parsed once, cache the output, and reuse it. With prompt caching, the cost of the parse input approaches zero on repeat queries. At the scales most production pipelines operate at, accuracy-per-dollar improves significantly.

Reducto is an agentic document platform that resolves layout, tables, figures, and cross-references into structured output that models can actually use. It takes one API call per document and the parsed output can be stored and reused across every subsequent query.
Get started with Reducto or book a demo to learn more. Additionally, if these types of problems excite you, apply to join our team on our careers page or check out our engineering blog.
Contributors: Apurv Gandhi and the Reducto ML team.
