
Parsing the 10-K: why financial filings defeat standard PDF pipelines
We've had some version of the same conversation with almost every financial team we work with. They've built the RAG pipeline with a capable language model and reasonable retrieval architecture, but the numbers coming back from 10-Ks are wrong. In almost every case, the problem turns out to be upstream of the model entirely. The parser had already lost the structure before the LLM ever touched the data, and the model was doing its job correctly on input that was already broken.
This post is our attempt to document exactly where that goes wrong. We cover what makes the SEC annual report specifically hard to extract reliably, the failure modes that show up repeatedly when generic PDF pipelines are pointed at financial filings, and what a parser actually needs to do to handle a 10-K correctly. We include benchmark numbers throughout, both from independent research and from our own testing on real filings.
Why the 10-K is a harder document than it looks
The 10-K is a good test case for document parsing because it concentrates several problems that are individually manageable but collectively break most pipelines.
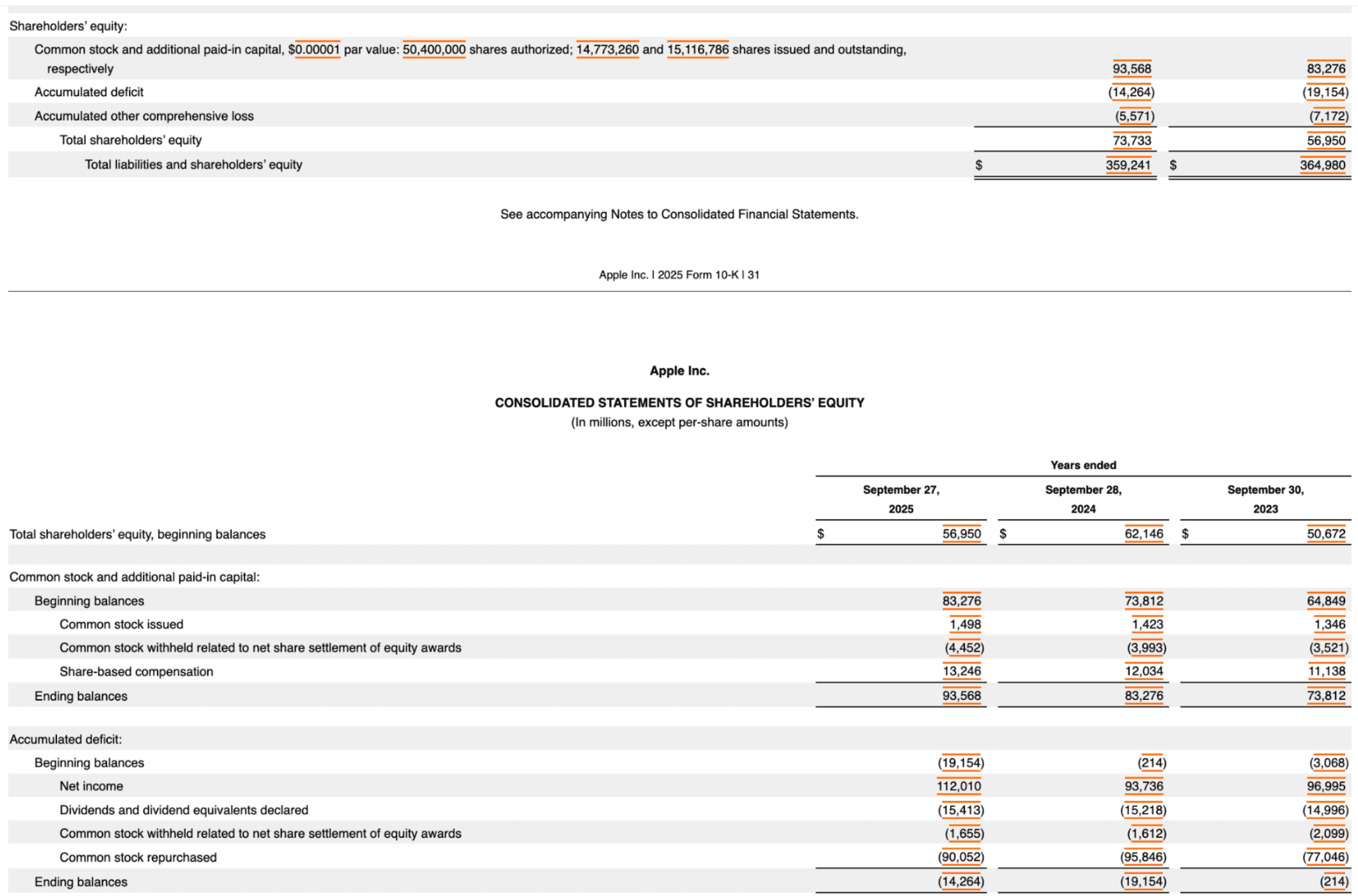
A single page from Apple's 2025 10-K. The top rows are the tail end of the Shareholders' Equity statement and the Cash Flow statement starts mid-page with its own header. A standard parser outputs those top rows as a detached block.
- Length and retrieval: Some annual reports exceed 1.1 million tokens, which is more than a one-million-token context window can hold. This means you can't process the document in one pass, but rather have to chunk it, embed the chunks, and retrieve the relevant pieces at query time. Any structural error introduced at the parsing step propagates forward through every downstream stage.
- Cross-referenced structure: A line item on the balance sheet typically points to a footnote (sometimes hundreds of pages away) that defines the accounting treatment or identifies contingencies. When you chunk a 10-K and sever those connections, the model answering questions from the retrieved chunks is working off incomplete context.
- Financial number conventions: Standard accounting practice writes negative values inside parentheses, such as (1,234) rather than -1,234. This is a convention that humans read automatically but that text-extraction pipelines frequently mishandle, either dropping the parentheses entirely or treating them as punctuation, resulting in a sign flip and a loss becoming a gain or a liability becoming an asset. Similarly, financial tables almost always include a scale declaration in the table header, which if dropped during parsing or chunking, every downstream value is wrong.
- Multi-page tables: A consolidated income statement or balance sheet regularly spans multiple pages, with the header row on one page and the data rows continuing across the next. Parsers that process documents page-by-page return those pages as separate, disconnected blocks, and without the header row attached, leaving data rows with no context about what each column and the units within represents.
- Multi-column layout: The narrative sections of a 10-K, particularly the MD&A, frequently use two or three-column layouts where related content sits side by side on the page. Extracting these correctly requires the parser to understand the physical structure of the page rather than just the left-to-right order of tokens in the text stream. The parsers that don't account for column boundaries will either interleave the two columns into scrambled prose or read one column twice while missing the other entirely.
Failure Modes
- Scale errors: An independent study ran an AI over 5,000 annual reports and found it misread numeric scale more than 8% of the time when reading the filing as plain text. Given the structured XBRL version of the same filings, that rate dropped to 0.11%. That's a 75x difference in error rate, and it comes entirely from parsing quality.
- Table structure: A model trained specifically on S&P 500 financial tables (FinTabNet) got the exact table structure right only 42% of the time on a standard benchmark.
- Sign handling: FinCriticalED, a benchmark focused on financial OCR failures, documents sign inversion as a named, recurring error class. GPT-4o scored 59.6% on numeric-fact questions about financial documents despite achieving over 90% accuracy on surface-level text.
These errors also have documented real-world costs when they occur in manual workflows, which may help provide a sense of the stakes involved.
A dropped minus sign on a $1.3 billion loss caused Fidelity's Magellan fund to issue a dividend estimate that was off by $2.6 billion, requiring a public retraction. PNC Financial disclosed losses through special purpose entities in footnotes rather than on-balance-sheet; the restatement cut 2001 earnings by $155 million and eventually cost roughly $405 million including penalties. Finally, a deferred tax misattribution across fiscal years drove a $399 million restatement at Molson Coors and almost an 8% stock decline.
Reducto’s Approach
We use a vision model to analyze the spatial structure of each page before any text extraction takes place. More vision-language models then read the content, and an agentic verification layer checks the outputs against the source image and corrects errors before returning results.
In practice, this translates to reassembled tables across page boundaries into coherent statements. Scale headers are tracked through the document and attached to the rows they govern, parenthetical negatives are returned as signed values, and every extracted field includes a bounding box and page citation.
Here's what structured extraction from a 10-K looks like with Reducto. We use Apple's most recent annual report as an example:
pythonfrom pathlib import Path from reducto import Reducto client = Reducto() upload = client.upload(file=Path("10k-apple.pdf")) result = client.extract.run( input=upload, instructions={ "schema": { "type": "object", "properties": { "company_info": { "type": "object", "properties": { "name": {"type": "string", "description": "Company name from cover page"}, "ticker": {"type": "string", "description": "Stock ticker symbol"}, "fiscal_year_end": {"type": "string", "description": "Fiscal year end date"}, "cik": {"type": "string", "description": "SEC CIK number"} } }, "income_statement": { "type": "object", "description": "Data from Consolidated Statements of Operations", "properties": { "total_revenue": {"type": "number", "description": "Total net sales/revenue in millions"}, "cost_of_sales": {"type": "number", "description": "Cost of goods sold in millions"}, "gross_profit": {"type": "number", "description": "Gross profit"}, "operating_expenses": {"type": "number", "description": "Total operating expenses"}, "operating_income": {"type": "number", "description": "Operating income"} } } } } }, settings={"citations": {"enabled": True}} # returns bounding box + page ref per field )
The citations setting is what gives you source attribution on every returned value. You can try this yourself on a real Apple 10-K through the financial analysis cookbook.
If you're evaluating vendors, ask for accuracy metrics on a named benchmark that covers those cases rather than aggregate scores, and treat source citations as a hard requirement rather than a nice-to-have, since in regulated contexts an answer you can't trace back to the source document isn't usable. The broader point is that the parsing layer sets the ceiling for everything built above it, so getting the structure right is the prerequisite for everything else working.
Get started with Reducto or book a demo to see how we handle financial filings at production scale.
Sources: FinCriticalED, FinanceBench, OHRBench, DocLayNet, FinTabNet / Table Transformer (public benchmarks). Restatement figures (Fidelity Magellan, Kodak, Hertz, PNC, Molson Coors) drawn from public SEC filings and press reports. Scale-error finding drawn from a published study across 5,000 annual reports.
