
Mistral OCR vs. Gemini Flash 2.0: Comparing VLM OCR Accuracy
Today, Mistral AI released a new OCR model, claiming to be state-of-the-art (SOTA) on unreleased benchmarks. We decided to put the model to the test.
As usual, folks on the internet got really excited. It trended to the top of HN and folks started claiming PDF parsing was solved forever:
PDF parsing is solved (again). Mistral's new OCR API — parses 1000-2000 pages for $1 — achieves state of the art results on tables, multilingual — supports structure: images, bounding boxes, scans, equations 90% of the world's organizational data is in PDFs.

At Reducto, we are constantly evaluating and testing various vision language models (VLMs) to thoroughly understand limitations in production use cases. We were the first provider to release an open parsing evaluation dataset, and decided to assess Mistral OCR qualitatively and quantitatively.
We benchmarked Mistral against Gemini 2.0 Flash as a point of comparison. Mistral reports that Gemini 2.0 has 88.49% accuracy on their internal dataset while Mistral OCR is reported as 94.9%. Since the benchmark isn't public we weren't able to assess this directly, but our testing revealed a meaningful discrepancy between the reported score and performance on our dataset.
Dense Table Page (Sample Financial Use Case)
We ran a page from a brokerage research report through both Gemini and Mistral's new OCR model. The results are depicted below.
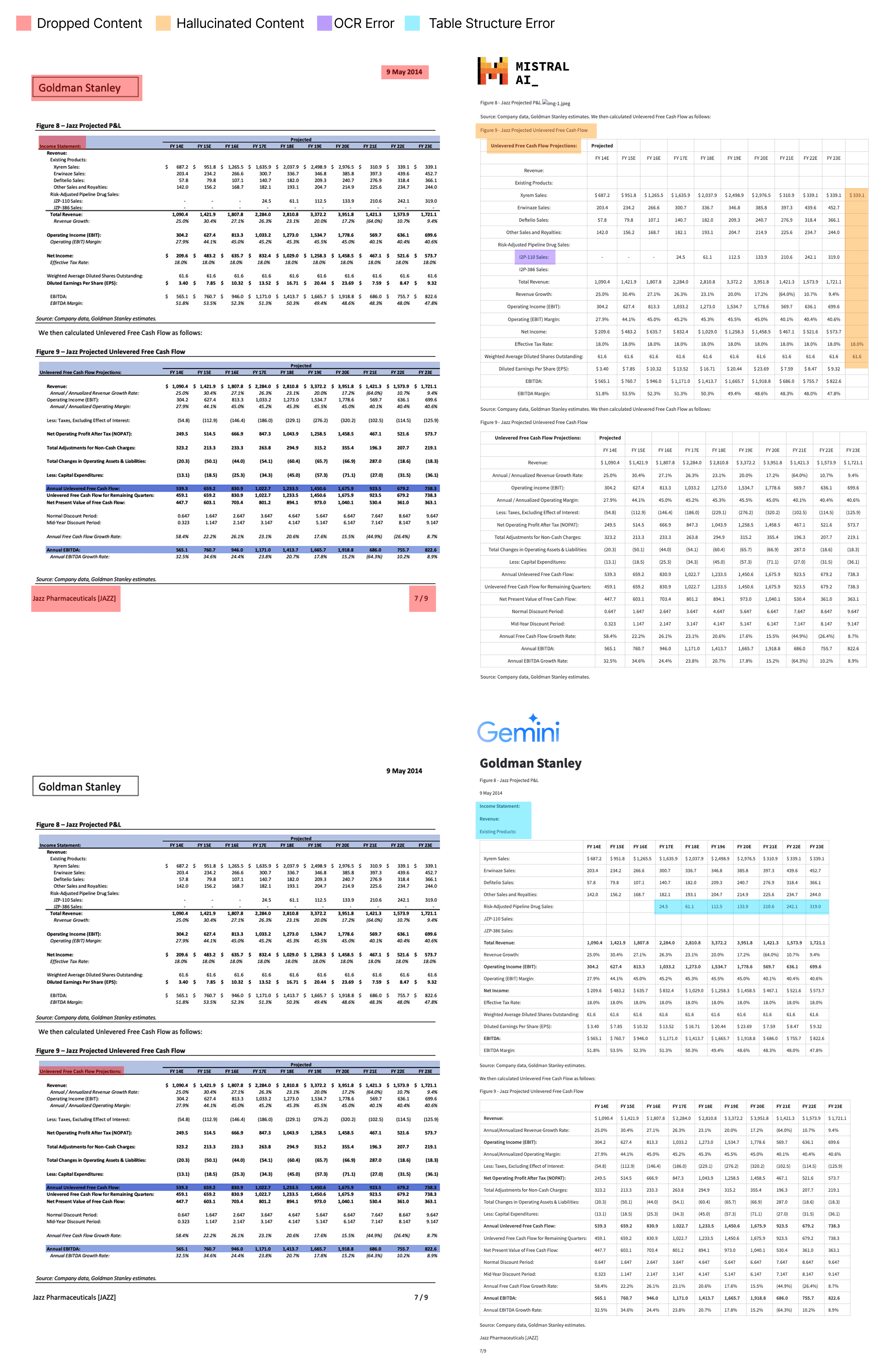
Overall, Gemini does a good job in capturing all of the content on the page. There are a few structural errors, where content from within the table is moved outside of the table. Additionally, one of the rows of the first table is shifted upward by one to incorrectly occupy an empty row. In general though, someone reading the generated markdown from Gemini would not be missing any information from the document and the overall content of the document is conveyed effectively.
On the other hand, for Mistral's OCR, we noticed a number of serious hallucinations which actually change the document content:
- Dropping header and footer information from the document overall.
- It outputs the first table as an image (incorrect layout classification). It then somehow repeats the table content after the fact of that first table with the incorrect headers and captions of the second table. This is a serious hallucination and would lead to a fundamentally different interpretation of the table contents.
- It adds a second column with some hallucinated repeated data to the first table.
- The header of the first table contains the information from the second table in the document.
- Some content from the header and footer of the document is missed. There are some OCR errors in reading the content
JZP-110 Salesis misread asI2P-110 Sales, etc.
Handwritten Form (Sample Medical Use Case)
We ran a sample page from a military medical incident report through both Gemini Flash 2.0 and Mistral's new OCR model.

In this case Gemini perfectly extracts the information without any errors.
For Mistral's OCR, we notice a few issues:
- Hallucinating that two checkboxes were actually unchecked instead of marking them as checked boxes.
- Dropping headers and footers from the page overall.
- Table structure mistakes which change the understanding of the document (Morphene is no longer labeled as an analgesic).
Alignment with Mistral's Benchmarks
Our "vibe check" of the models doesn't at all align with the benchmarks posted on Mistral's blog.
| Model | Overall | Math | Multilingual | Scanned | Tables |
|---|---|---|---|---|---|
| Google Document AI | 83.42 | 80.29 | 86.42 | 92.77 | 78.16 |
| Azure OCR | 89.52 | 85.72 | 87.52 | 94.65 | 89.52 |
| Gemini-1.5-Flash-002 | 90.23 | 89.11 | 86.76 | 94.87 | 90.48 |
| Gemini-1.5-Pro-002 | 89.92 | 88.48 | 86.33 | 96.15 | 89.71 |
| Gemini-2.0-Flash-001 | 88.69 | 84.18 | 85.80 | 95.11 | 91.46 |
| GPT-4o-2024-11-20 | 89.77 | 87.55 | 86.00 | 94.58 | 91.70 |
| Mistral OCR 2503 | 94.89 | 94.29 | 89.55 | 98.96 | 96.12 |
Source: mistral.ai/news/mistral-ocr.
Digging deeper we find that their benchmarking dataset is non-public:
internal 'text-only' test-set containing various publication papers, and PDFs from the web
It's possible the data used for this benchmark comes from a similar distribution to that used to train the model itself, which could explain the incongruency in the results. For a more fair comparison, we also decided to test the two models with our upcoming RD-FormsBench dataset which measures LLM extraction performance as a function of different parsing solutions.
This dataset is composed of 1000 diverse documents including scenarios with handwriting, multiple languages, checkboxes, and complex layouts. With this dataset we find that Mistral OCR is 43.4% less accurate than Gemini 2.0 Flash.
| Model | RD-FormsBench Accuracy |
|---|---|
| Gemini | 80.1% |
| Mistral | 45.3% |
Analyzing loss cases
Our benchmarking results for Mistral were surprisingly low. Further investigation revealed that, on complex documents, the model frequently marked large sections as images and returned cropped images without OCR data. This OCR data is essential for accurate evaluation. Although one could pass these images directly to a VLM, this would almost equate to providing a full page to the language model, making it an unfair comparison when benchmarking OCR and parsing methods.

Solving Document Processing
We're going to open source this dataset alongside results for other models in an upcoming release.
Our goal is to create a more comprehensive reference point for model advancements that capture the challenging scenarios companies face in the real world. Document processing isn't solved yet, but we're very excited by the improvements across the industry, and are optimistic about the potential for vision models to redefine the state of the art.
